Web實戰開發 — 百萬級爬蟲服務架構的總體設計與開發
隨著互聯網數據爆炸式增長,高效、穩定的爬蟲服務成為企業數據獲取的核心工具。尤其在百萬級數據爬取場景下,系統需兼顧性能、可擴展性和容錯能力。本文將詳細探討百萬級爬蟲服務架構的總體設計思路與軟件開發實現。
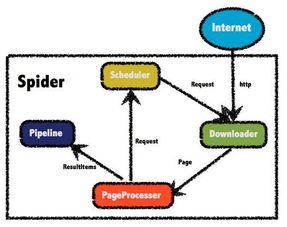
一、總體架構設計
- 模塊化分層結構
- 調度層:負責任務分配與優先級管理,采用分布式任務隊列(如Redis、RabbitMQ)實現負載均衡。
- 爬取層:由多個爬蟲節點組成,支持多線程/協程并發,通過IP代理池和User-Agent輪換規避反爬機制。
- 解析層:集成HTML解析庫(如BeautifulSoup、lxml)與正則表達式,提取結構化數據。
- 存儲層:采用混合存儲方案,關系型數據庫(如MySQL)存儲元數據,NoSQL(如MongoDB、Elasticsearch)存儲非結構化數據,結合緩存(如Redis)提升讀寫效率。
- 監控層:實時收集節點狀態、請求成功率等指標,通過Prometheus和Grafana實現可視化告警。
- 高可用與擴展性設計
- 采用微服務架構,各模塊可獨立部署和水平擴展。
- 引入容器化技術(如Docker + Kubernetes),實現快速彈性伸縮。
- 設計容錯機制:任務重試、節點心跳檢測、數據去重(布隆過濾器)等。
二、軟件開發與實現
- 技術棧選擇
- 開發語言:Python(Scrapy框架)或Go(高并發優勢)。
- 消息隊列:Redis或Kafka,保障任務有序分發。
- 代理與反反爬:集成第三方代理服務(如快代理),結合動態Cookie管理與請求頻率控制。
- 核心開發流程
- 任務調度:通過Celery或自定義調度器實現分布式任務管理。
- 異步爬取:利用asyncio或Gevent提升I/O密集型任務效率。
- 數據清洗:在解析層嵌入數據驗證規則,確保數據質量。
- 存儲優化:采用分庫分表策略,結合索引優化查詢性能。
- 測試與部署
- 單元測試覆蓋爬蟲邏輯與解析規則。
- 壓力測試模擬高并發場景,驗證系統瓶頸。
- 使用CI/CD工具(如Jenkins、GitLab CI)自動化部署與更新。
三、挑戰與優化方向
- 反爬策略應對:持續更新User-Agent池與IP代理,模擬人類行為。
- 資源控制:限制單節點帶寬與請求頻率,避免對目標站點造成壓力。
- 法律與倫理:遵循robots.txt協議,確保數據采集合法性。
百萬級爬蟲服務架構需在性能、穩定性和可維護性間取得平衡。通過模塊化設計、分布式技術與自動化運維,可構建高效可靠的數據采集系統,為業務決策提供強力支持。
如若轉載,請注明出處:http://m.villkov.cn/product/6.html
更新時間:2026-02-24 15:17:05